阿里云李飞飞 数据与数据处理,超级AI的“燃料”与“引擎”

在近日的一场技术峰会上,阿里云智能数据库事业部负责人李飞飞博士再次强调了数据与数据处理在人工智能发展进程中的核心地位。她用一个形象的比喻指出:对于通往超级人工智能(AI)的征途而言,数据是必不可少的“燃料”,而强大的数据处理与存储服务则是驱动其前进的“引擎”。这一论述深刻揭示了在AI模型规模急剧膨胀、智能水平持续跃升的当下,底层数据基础设施所扮演的关键角色。
李飞飞指出,我们正处在一个数据爆炸的时代,海量、多模态的数据是训练更先进、更通用AI模型的基石。就像高性能发动机需要高纯度的燃油一样,超级AI的“智能”高度依赖于高质量、大规模的训练数据。这些数据不仅包括传统的文本、数字,更涵盖了图像、音频、视频、传感器信息等多元形态,构成了AI认知和理解世界的原始素材。没有持续、优质的数据供给,AI的演进就会成为无源之水。
仅仅是拥有海量“燃料”并不足够。李飞飞着重强调了“引擎”——即数据处理与存储服务——的重要性。原始数据往往是非结构化的、杂乱无章的,其价值需要通过一系列复杂的处理流程才能释放。这包括数据的采集、清洗、标注、治理、集成与分析。面对超大规模的数据集,传统的数据处理技术已力不从心,必须依赖云计算所提供的高弹性、高并发、智能化的数据处理平台与服务。
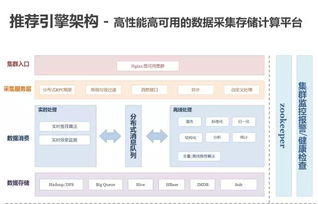
阿里云作为全球领先的云服务提供商,正在致力于打造这一核心“引擎”。其提供的数据处理与存储服务,如大数据计算平台MaxCompute、实时数据仓库Hologres、一站式数据平台DataWorks以及高性能的云原生数据库PolarDB等,构成了一个完整的数据智能引擎矩阵。这些服务旨在实现数据在存储、处理、流动与管理上的极致效率与极低成本,能够支撑从千亿参数大模型训练到实时智能决策的各类苛刻场景。它们不仅处理速度快,更能智能地优化数据布局、自动进行资源调度与故障恢复,确保数据流水线始终高效、稳定地运转。
李飞飞进一步阐释,未来的数据处理范式正在向“Data+AI”融合的方向演进。数据处理系统本身将深度集成AI能力,实现自优化、自管理、自运维;AI模型的生命周期管理也反过来对数据处理提出了更高要求,如支持海量检查点(Checkpoint)的快速保存与恢复、训练过程中数据的动态加载与预处理等。这就对底层存储的吞吐能力、I/O性能以及计算与存储协同架构提出了前所未有的挑战。
她道,通往超级AI的道路是一场漫长的马拉松,其进程并非仅仅由算法模型的突破所单独决定。坚实、敏捷、智能的数据处理与存储基础设施,是确保“数据燃料”能够持续、高效转化为“智能动力”的根本保障。阿里云将持续投入,不断强化这具“引擎”的性能与智能化水平,与业界共同努力,为人工智能的下一阶段发展铺就坚实的数据基石,推动数据价值向智能成果的高效转化。
如若转载,请注明出处:http://www.rejfdrw.com/product/64.html
更新时间:2026-06-19 13:28:52