Spark运行原理与RDD解密 数据处理和存储服务
Apache Spark是一个开源的大数据处理框架,以其高速、易用和通用性而闻名。它通过高效的内存计算和优化的执行引擎,显著提升了大数据处理任务的性能。本文将深入解析Spark的运行原理,并解密其核心抽象——弹性分布式数据集(RDD),同时探讨其在数据处理与存储服务中的应用。
一、Spark运行原理:分布式计算的引擎
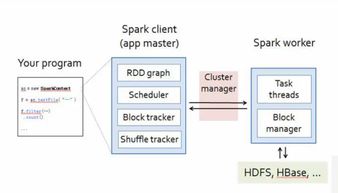
Spark的运行基于主从架构,主要由Driver程序、Cluster Manager和Executor组成。Driver程序负责解析用户代码,将任务拆分为多个阶段(Stages),并通过DAG(有向无环图)调度器优化执行顺序。Cluster Manager(如Standalone、YARN或Mesos)管理集群资源,分配Executor给各个任务。Executor运行在Worker节点上,执行具体的计算任务,并将结果返回给Driver。
关键特性包括内存计算和惰性执行:Spark将数据尽可能保留在内存中,减少磁盘I/O开销;而惰性执行意味着转换操作(如map、filter)不会立即执行,只有在遇到行动操作(如collect、count)时才触发计算,这允许Spark进行整体优化。
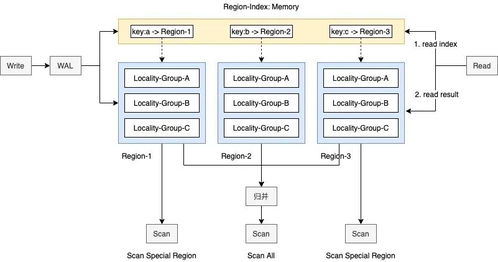
二、RDD解密:弹性分布式数据集的核心
RDD是Spark的基本数据结构,代表一个不可变、分区的分布式对象集合。它具有以下关键特性:
- 弹性(Resilient):通过血缘关系(Lineage)实现容错。如果某个分区数据丢失,Spark可以根据血缘信息重新计算,而无需复制数据。
- 分布式(Distributed):数据被分割成多个分区,分布在集群节点上,支持并行处理。
- 数据集(Dataset):可以是任何数据类型,如文本、数字或对象。
RDD支持两种操作:转换(Transformations)和行动(Actions)。转换操作(如map、flatMap)生成新的RDD,而行动操作(如reduce、saveAsTextFile)触发计算并返回结果。这种设计使得Spark能够高效处理迭代式算法和交互式查询。
三、数据处理与存储服务:Spark的实际应用
Spark在数据处理和存储服务中发挥重要作用,主要体现在:
- 数据处理:通过RDD和高级API(如DataFrame和Dataset),Spark支持ETL(提取、转换、加载)、流处理(Structured Streaming)和机器学习(MLlib)。例如,在实时数据流中,Spark可以持续处理来自Kafka的数据,并输出到HDFS或数据库中。
- 存储服务集成:Spark与多种存储系统无缝集成,包括HDFS、Amazon S3、HBase和Cassandra。用户可以直接从这些存储中读取数据到RDD,处理后再写回,实现高效的数据流水线。
Spark的运行原理和RDD设计使其成为大数据处理的核心工具。通过理解这些机制,用户可以优化应用性能,构建可靠的数据处理服务。随着Spark生态的不断发展,它在云存储和实时分析领域的应用将进一步扩展。
如若转载,请注明出处:http://www.rejfdrw.com/product/21.html
更新时间:2026-06-09 13:50:34