数据仓库架构及三大类组件工具选型综述
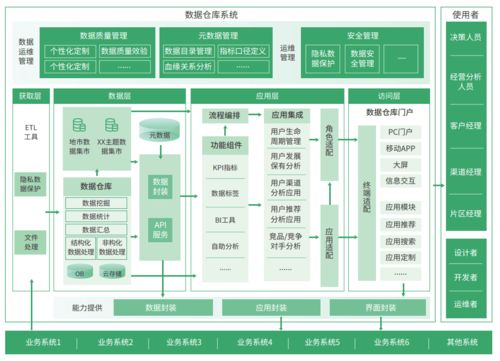
数据仓库是支持企业决策的关键基础设施,集成了来自多个异构数据源的数据,经过加工、转换后提供统一的分析视图。其架构设计及组件工具的选型直接影响数据处理的效率、存储的可靠性及服务的可用性。本文将系统阐述数据仓库的典型架构,并聚焦数据处理与存储服务,详细介绍三大类核心组件的工具选型。
一、数据仓库的典型架构
数据仓库的架构通常遵循分层设计,以支持数据的流动与治理。核心层次包括:
- 数据源层:来源多样的业务系统、日志、外部数据等。
- 数据集成层(ETL/ELT):负责数据的抽取、转换和加载。
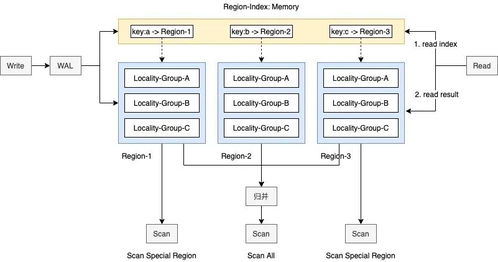
- 数据存储层:存储清洗和整合后的数据,包括ODS(操作数据存储)、数据仓库及数据集市。
- 数据服务层:提供数据查询、API接口及分析服务。
- 应用层:支持BI工具、报表系统及数据应用。
其中,数据处理与存储服务位于集成层与存储层,是数据仓库的核心支撑。
二、数据处理和存储服务的三大类组件工具选型
根据功能定位,可将数据仓库中涉及数据处理与存储服务的组件工具划分为三大类:数据集成工具、数据存储引擎及数据处理框架。
1. 数据集成工具
数据集成工具负责从源系统抽取数据,并进行清洗、转换和加载到目标存储。选型需考虑数据源兼容性、实时性要求及运维复杂度。
- 传统ETL工具:如Informatica PowerCenter、IBM DataStage,适合复杂业务逻辑和高度可靠性的批处理场景,但成本较高。
- 开源ETL工具:如Apache NiFi、Talend Open Studio,提供可视化数据流设计,支持多种数据源,适合预算有限且需要灵活定制的环境。
- 云原生数据集成服务:如AWS Glue、Azure Data Factory,具备弹性扩展、托管服务等优势,适合云上部署和自动化运维。
选型建议:根据企业IT环境(云上或本地)、实时性需求(批处理或流式)及团队技能进行综合评估。
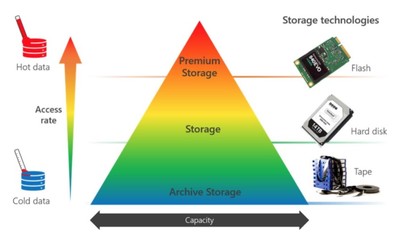
2. 数据存储引擎
数据存储引擎承载清洗后的数据,需满足高吞吐、低延迟查询及可扩展性。根据数据模型和应用场景,可分为以下几类:
- 关系型数据仓库:如Teradata、Amazon Redshift、Snowflake,支持标准SQL和复杂查询,适合结构化数据的分析场景。
- 大数据存储平台:如Hadoop HDFS、Apache HBase,适用于半结构化和非结构化数据的存储,常与计算框架(如Spark)结合使用。
- 实时数据存储:如Apache Druid、ClickHouse,专为低延迟分析查询设计,适合实时监控和交互式分析。
选型建议:结合数据量级、查询性能要求及架构一致性(如是否与现有Hadoop生态集成)进行选择。
3. 数据处理框架
数据处理框架提供数据转换、计算及流处理能力,是数据仓库中实现数据价值的关键。
- 批处理框架:如Apache Spark、Apache Hive,适用于大规模历史数据的ETL和聚合计算。
- 流处理框架:如Apache Flink、Apache Kafka Streams,支持实时数据流的处理,适合风控、实时推荐等场景。
- 混合处理框架:如Apache Beam,提供统一的编程模型,可同时在批和流模式下运行,提升开发效率。
选型建议:根据业务对实时性的需求、数据处理的复杂度及团队对框架的熟悉程度来决定。
三、总结
数据仓库的架构设计与组件工具选型是一个系统性工程,需综合考虑数据特性、业务需求及技术生态。在数据处理与存储服务方面,通过合理选型数据集成工具、数据存储引擎和数据处理框架,能够构建高效、可扩展的数据仓库平台,为企业数据分析与决策提供坚实基础。随着云原生与AI技术的融合,数据仓库架构及工具将朝着更智能、更自动化的方向发展。
如若转载,请注明出处:http://www.rejfdrw.com/product/20.html
更新时间:2026-06-09 18:32:21